
对我而言,开发最容易踩到坑踩到屎的就是 iOS 开发,其次是 Windows 开发。
归其原因,一般我接触到的 C++ 开发都是以类 unix 系统作为开发的(MacOS、Android、Linux),所以作为不同源且自成门派的 Windows 系统开发对我来说,开发的时候就能感受到很多割裂感,比如 Windows 特有的各种 winAPI,以及不同于类 unix 系统的各种习惯。(例如回车是 LRLF,Visual Studio 文件编码之类的)。
这次可是吃了一坨大的,也多亏于此我对于文件的编码有了更深的认识。
接下来就讲一下我的探索之旅。
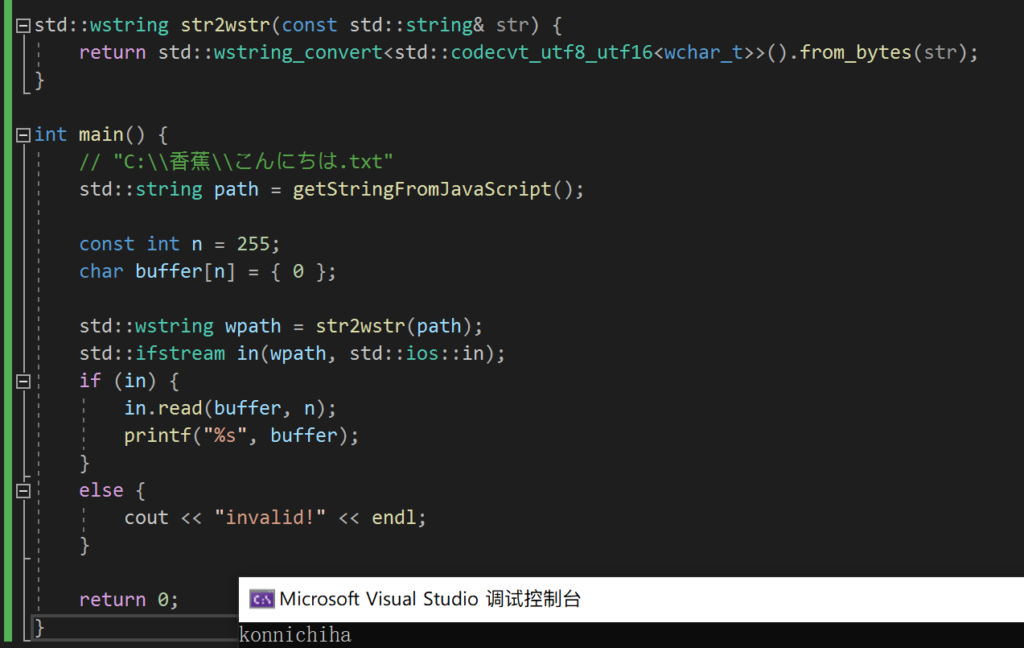
这次遇到了这么一个问题:通过 ffi-napi (理解成 JavaScript 调用 C++ dll 的桥梁就行)向 C++ 传入 windows 路径时,找不到存在的文件:
举个例子模拟一下:
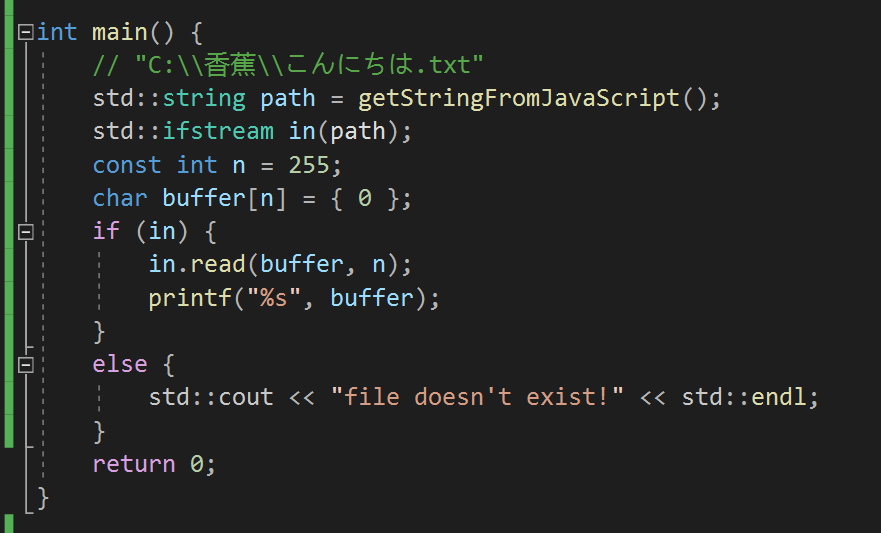
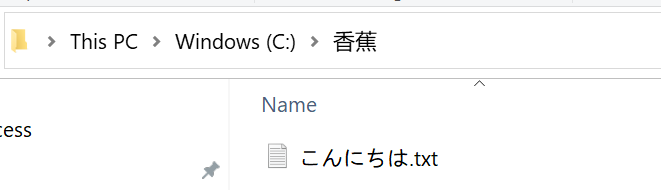
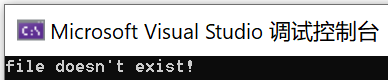
为什么明明文件存在,却无法通过这个路径找到这个文件呢?
有可能是文件打开失败,有可能是文件名编码错误,但总之可以先 Debug 断点看一下发生了什么:
字符串在内存中的样子
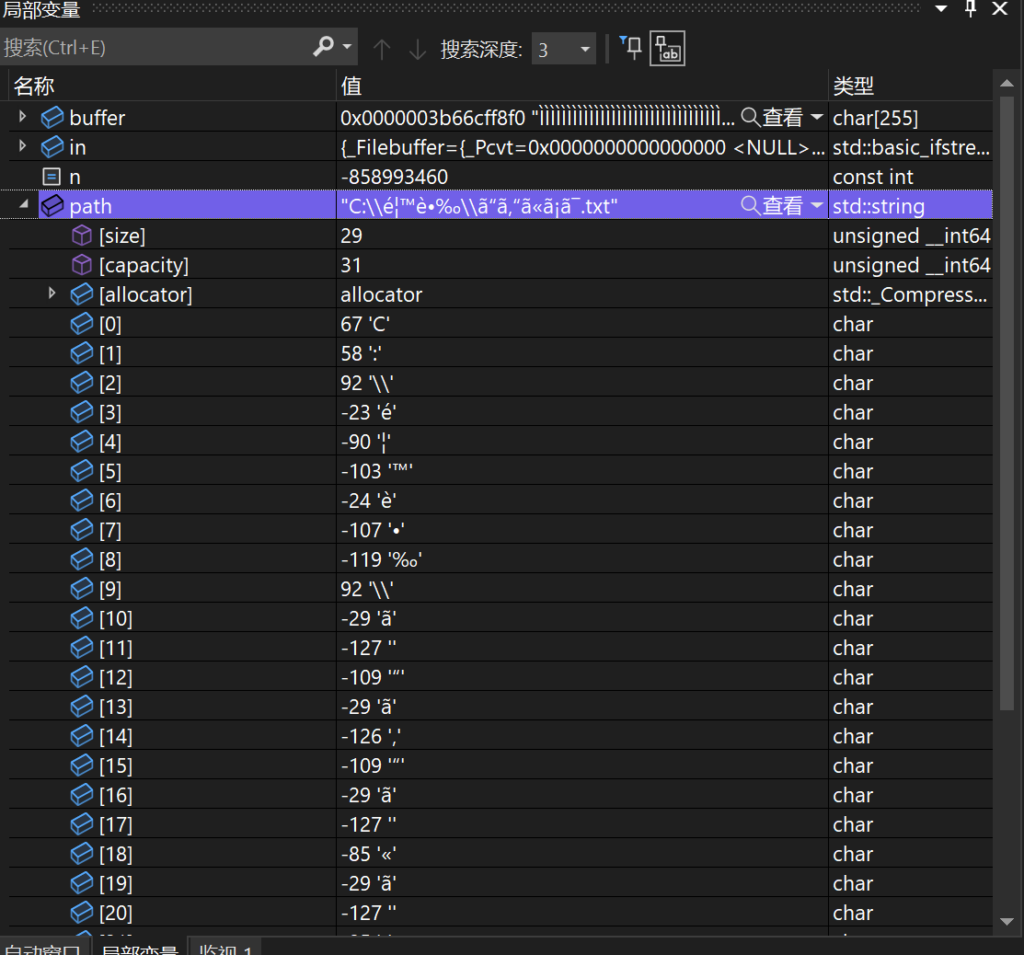
可以看到,路径只有 ASCII 字符是显示正常的,其他的都显示成了一些拼音乱码,看来这很有可能就是找不到文件的原因:路径编码错误。
那么应该怎么解决呢?
让 Windows 正确编码路径
TL;DR(太长不看)
C++ 有一种宽字符类型叫 wchar_t,有一种宽字符串类型叫 std::wstring,这两种神奇的类型可以正确识别 Windows 下的 Unicode 字符路径。
把路径的 string 转换成 wstring,再传入文件的构造函数就可以了。
对于一般的 winAPI,基本都会有宽字符版本的 API,涉及到路径的都改成宽字符版本就行了。
// 这个利用的是 C++ 标准提供的方法,C++11 开始存在,C++17 开始被标为 deprecated
std::wstring str2wstr(const std::string& str) {
return std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>>().from_bytes(str);
}
// 这个利用的是 Windows 提供的 API,应该和标准无关,都能用
std::wstring utf8_to_utf16(const std::string& str) {
std::wstring wstr(MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, NULL, 0), L'0');
MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, &wstr[0], wstr.size());
return wstr;
}
如果你只是想来找解决方案而不是想知道具体原理的话,现在就可以离开这个页面了,因为接下来会有很多又臭又长的概念。
reference:
std::codecvt_utf8_utf16 – cppreference.com
MultiByteToWideChar function (stringapiset.h) – Win32 apps | Microsoft Docs
又臭又长的原理解析
内存里的字符串是什么?
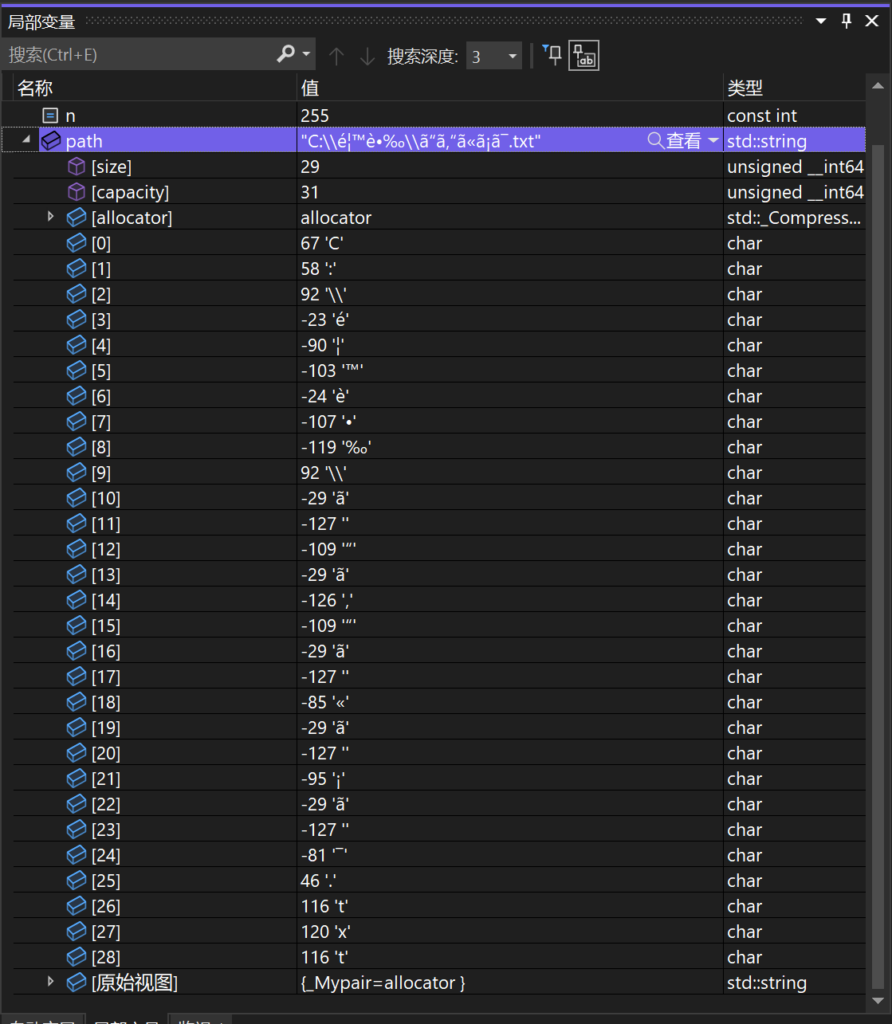
可以看到,中文和日文这些不在 ASCII 码范围内的字符是不止用一个字节存储的,看两个 ‘\\’ 之间 [3, 8] 一共用了 6 个字节来存储 “香蕉” 两个字。
3 个字节存一个中文字,这种特征很符合目前最常用的字符编码格式:utf-8,让我们写一个 python 脚本来协助分析一下。
def pdec(str, method):
code = str.encode(method)
byte_list = []
for c in code:
if c > 127:
byte_list.append(c - 256)
else:
byte_list.append(c)
print("\n".join("{:d}".format(c) for c in byte_list))
def phex(str, method):
code = str.encode(method)
print(":".join("{:02x}".format(c) for c in code))
ok = 'C:\\香蕉\\こんにちは.txt'
pdec(ok, 'utf-8')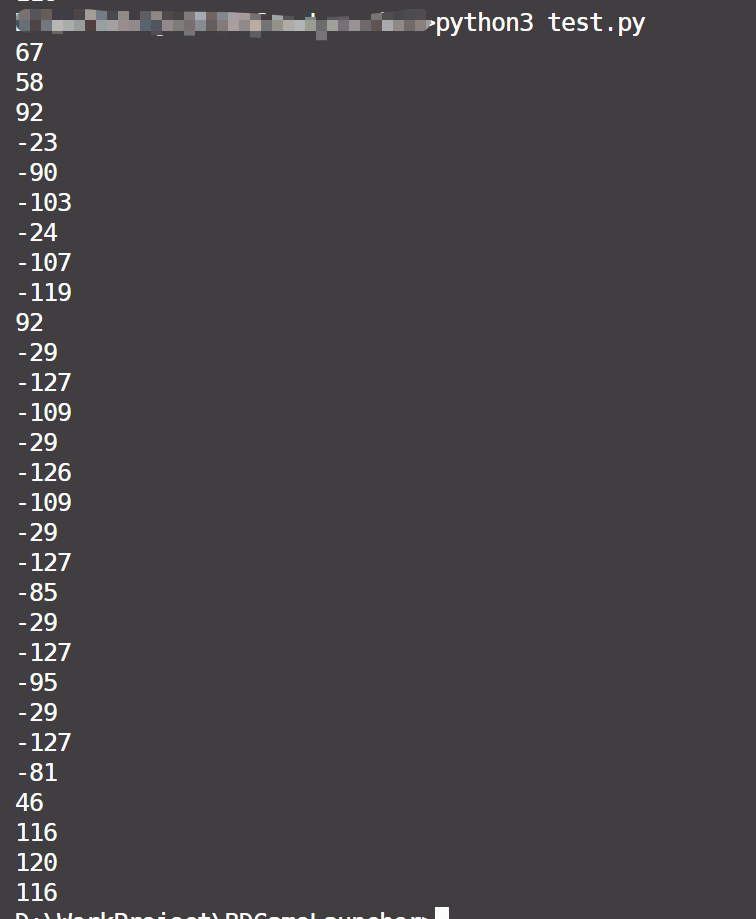

可以看到,两者的字节一模一样,从而可以得出第一个结论:
JavaScript 传进来的字符内部是以 utf-8 进行编码的。
为什么 Windows 没法识别 utf-8 编码的文件路径?
这个问题看上去很简单,但实际上要解释完整需要一个很宽的视野,就跟要认识当今世界局势就得先学习世界历史一样,要理解软件现状就得先学习软件发展的历史。为了解释这个大问题,我们需要学习这些前置知识:
- 编码的发展历史
- windows 编码的发展
编码和编码方式
彻底弄懂Unicode编码 – 李宇仓 | Li Yucang (liyucang-git.github.io)
看这篇就好了,这篇写得很好,以下是太长不看的总结:
ASCII
美国信息交换标准代码,大家最熟悉的,不多说了。因为是美国人发明的,所以只包含了他们的母语英语的字母。
范围是 0 ~ 127,换成 16 进制就是 0x00 ~ 0x7f,一共占用 7 个 bits,涵盖了英文字母以及常用的符号。
ANSI
ASCII 只有英文字母,非英语母语的国家自然需要其他方式表示自己母语的编码方式,所以就有了 ANSI 编码。
ANSI 编码其实算是一个比较「相对」的叫法,就像「我国」一样。如果一个中国人说「我国」,这里的「我国」则指中国,如果一个英国人说「我国」,则这里的「我国」指英国,ANSI 也是如此,各国所称的 ANSI 其实指的是不同的编码。
ANSI 基本上都是 ASCII + 本地语言扩展,不同的 ANSI 编码之间互不兼容。
在简体中文语境下,ANSI 一般指 GBK 编码。
GBK 编码完全兼容 ASCII,也包含中文字符。
0x00~0x7F 之间的字符(也就是 ASCII),依旧是 1 个字节代表一个字符。对于中文字符,则用 2 个字节代表一个字符。例如「用」的 gbk 编码是 0xd3 0xc3。
Unicode
如果每个语言都有自己的编码方式,而且相互不兼容,不仅不好管理,做兼容也麻烦到飞天,所有就有一群人想发明一种全世界都统一的编码方式,所以就有了 unicode。
unicode,目前全球最流行的字符集,包含了所有目前人类语言的极大部分字符,emoji 也是 unicode 的一部分。
每一个字符都有独一无二的编号。Unicode 只规定了每个字符的编号是什么,并没有规定这些编号要通过什么样的形式去编码存储。
UTF-8
目前最流行的 Unicode 编码方式。长度不定,完全兼容 ASCII。
现在的 utf-8 编码一般占用 1-4 个字节。中文字符一般用 3 个字节来存储。
UCS-2
基本已经被淘汰的编码方式。每个字符统一占用 2 个字节。
后来 unicode 符号变得越来越多,2 个字节不够用了,被 utf-16 所替代。
UTF-16
没有 utf-8 那么流行的 Unicode 编码方式,UCS-2 的超集。
字符要么占用 2 个字节,要么占用 4 个字节。
(冷知识:其实很多页面的「字符转 Unicode」工具,实际上转换成的是 utf-16)
UTF-32
比 utf-16 还要不流行的 Unicode 编码方式,每个字符统一占用 4 个字节。
Windows 的编码发展
众所周知,Windows 对于向后兼容这件事可以说是极为疯狂的。win98 时代的程序,在 win11 都还能用兼容模式跑起来。但兼容的代价就是一堆历史遗留问题所带来的麻烦,在编码上也如此。
旧时代 Windows 怎么解决非英文编码问题
首先作为一个操作系统,支持 ASCII 是肯定的。但是 Windows 并不是只支持英文这一种语言,那么其他语言的编码应该怎么表示呢?
所以在 Windows 3.1 ~ Windows 9x 时代,为了支持非 ASCII 字符,Windows 引入了代码页,代码页规定了非 ASCII 编码如何显示,不同的代码页对于相同的数值映射着不同的字符。虽然不太准确,但方便理解可以认为,ANSI 编码 == 代码页。
官方说明:Code Pages – Win32 apps | Microsoft Docs
直到现在对于一些比较老的程序也还是使用这种方式来兼容。也就是说,处理非 ASCII 字符的时候,就用当前代码页所指定的编码方式去对非 ASCII 字符进行解码。
但是不同国家的 ANSI 编码是不同的,如果用本地的 ANSI 编码打开另一个 ANSI 编码的内容,则会出现乱码。

打开 cmd,在标题右键 -> 属性,能看到我的电脑当前代码页编码是 GBK。
新时代 Windows 怎么解决 Unicode 编码问题
随着时代发展,Unicode 出现了,大家都开始用 Unicode,所以 Windows 自然而然也得支持 Unicode。
到 Windows NT 内核时代,Windows 2000 为了支持 Unicode,内核当时选用的是 UCS-2 编码,当年的 Unicode 数量并不多,UCS-2 本身是可以保证 2 个字节表示「所有 Unicode 字符」的。但随着 Unicode 集合的增大,UCS-2 不能够满足需求了,所以 Windows 对 Unicode 的编码换成了完全兼容 UCS-2 的 utf-16。
所以,现代的 windows 对于 unicode 的支持,底层编码都是用的 utf-16。官方文档是这么说的:
The character set most commonly used in computers today is Unicode, a global standard for character encoding. Internally, Windows applications use the UTF-16 implementation of Unicode.
Character Sets – Win32 apps | Microsoft Docs
(顺带一提,把这个链接里面的 Character Sets 整章给看完,基本上就能够理解 Windows 内的编码是如何运作的了)
可能大家会问,明明现在最流行的是 utf-8,为什么 Windows 要用 utf-16 呢?无他,只是历史原因。utf-8 出现得比 ANSI 晚,utf-8 出现的时候, Windows 已经支持中文了,所以 Windows 只能用 ANSI。
后来 Windows NT 内核采用的是 UCS-2,当 UCS-2 淘汰之后,为了兼容性,采用完全兼容 UCS-2 的 utf-16 也是非常自然的事情。
在 Visual Studio 中支持 Unicode
Windows API 对宽字符的支持
Wide characters encoded using UTF-16LE (for little-endian) are the native character format for Windows.
Support for Unicode | Microsoft Docs
Windows natively supports Unicode strings for UI elements, file names, and so forth.
Working with Strings – Win32 apps | Microsoft Docs
Windows represents Unicode characters using UTF-16 encoding, in which each character is encoded as one or two 16-bit values. UTF-16 characters are called wide characters, to distinguish them from 8-bit ANSI characters.
通过翻阅微软官方文档可以得知,utf-16le(小端序的 utf-16) 是 windows 在 C++ 里的宽字符原生编码。
也就是说,windows 的 API 原生支持传入编码为 utf-16 的宽字符类型,windows 是认得出来的,不会像 utf-8 编码的 std::string 那样被解成乱码。
宽字符的类型是 wchar_t,在 windows 里,sizeof(wchar_t) == 2,也就是 2 个字节,是 char 的两倍长度。
宽字符串的字符串字面量格式为 L"",例如 L"你好呀" 的类型就是 wchar_t* 。与 std::string 对应的宽字符串类型为 std::wstring。
两种WinAPI
现在的 WinAPI 一般都会提供对宽字符的支持,但是支持的形式不太一样。
第一种:API 名字不同
这种 API 包括 fopen 和 _wfopen,remove 和 _wremove 等。char 和 wchar_t 分别使用不同名字的 API。这些 API 一般 char 版为 C/C++ 标准自带的函数,然后 MSVC(Microsoft Visual C++)编译器再提供一个 wchar_t 版本用于支持宽字符。
这些 API 在使用的时候,需要使用者自行区分是否应该调用宽字节版本。
第二种:API 名字相同,实现通过宏定义分割
这些 API 包括 PathFileExists,SetWindowText 等。如同 Working with Strings – Win32 apps | Microsoft Docs 里所描述的:


这些 API 在使用的时候,只需要把字符串传进去即可,不需要使用者判断应该使用 A 后缀的 API 还是 W 后缀的 API。
总结:在 WinAPI 中,windows 会把字符串当做 ANSI 编码处理,把宽字符串当做 utf-16 编码处理。
UNICODE 这个宏是在哪定义的(补充章节,不看也行)
在 Visual Studio 中,对工程右键 -> 属性 -> 配置属性 -> 高级里,有个「字符集」,选择「使用 Unicode 字符集」
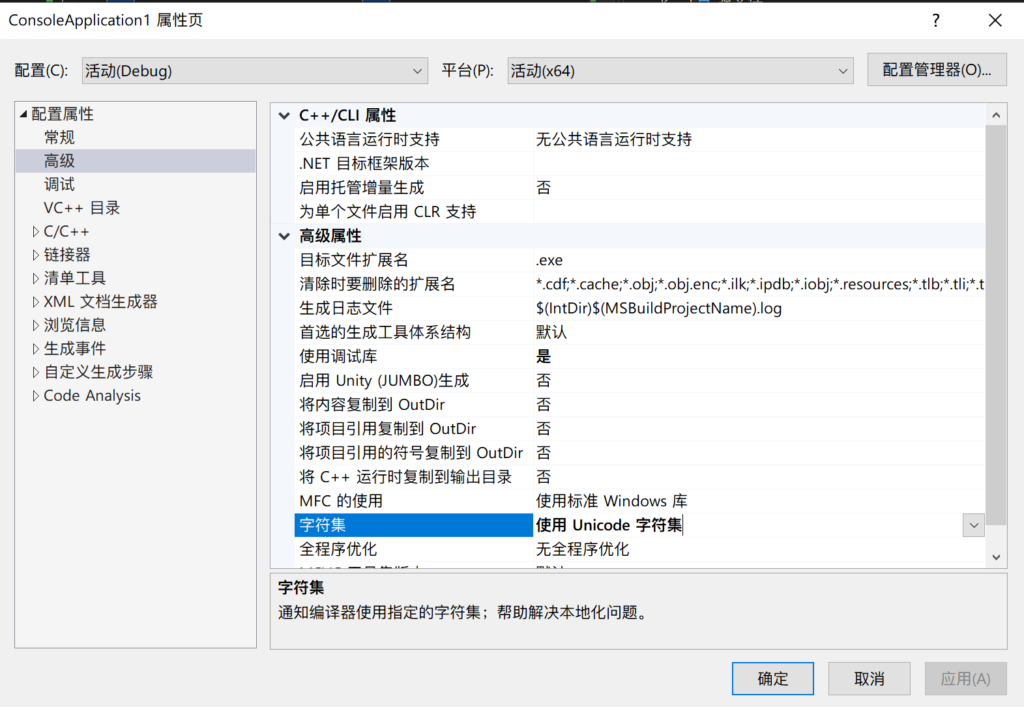
点击应用,再转到 C/C++ -> 命令行,就可以看到定义 UNICODE 和 _UNICODE 的编译器参数:

如果不是使用 Visual Studio 创建工程,而是使用 CMake 或者自行调用命令行,则需要自己在配置或者参数里加上 UNICODE 和 _UNICODE 的定义。
如何得到 utf-16 编码的宽字符串
C++ 标准提供的方法
从 C++11 开始,C++ 标准提供了 std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>> 类作为从 utf-8 编码的 std::string 和 utf-16 编码的 std::wstring 的相互转换工具。(但是 C++17 又被标为 deprecated 了,真的是反复横跳)。
cppreference 对该类的介绍:std::codecvt_utf8_utf16 – cppreference.com
调用该类的 from_bytes() 方法,输入 utf-8 编码的 std::string ,就能得到 utf-16 编码的 std::wstring。
封装一下,就可以得到这么一个函数:
std::wstring str2wstr(const std::string& str) {
return std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>>().from_bytes(str);
}Windows 提供的方法
MultiByteToWideChar function (stringapiset.h) – Win32 apps | Microsoft Docs
MultiByteToWideChar() 是 Windows 提供的一个把 char 字符串转为 wchar_t 字符串的方法,不仅支持从 utf-8 到 utf-16,还支持其他代码页编码的 ANSI 字符转为 utf-16 编码的 wchar_t 字符串。
具体使用方式可以看上面的链接,里面写得很清晰,这里就不重复介绍了
封装一下,就可以得到这么一个函数:
std::wstring utf8_to_utf16(const std::string& str) {
std::wstring wstr;
int wchar_num = MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, NULL, 0);
wstr.resize(wchar_num);
MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, &wstr[0], wchar_num);
return wstr;
}解答
那么,现在来回答最开始的问题:为什么 Windows 没法识别 utf-8 编码的文件路径?
因为 Visual Studio 的 Debugger 走不进构造方法里,所以我们使用 CLion跟着 Debugger,走进 std::ifstream 的构造方法之内,可以看到这么一个函数:
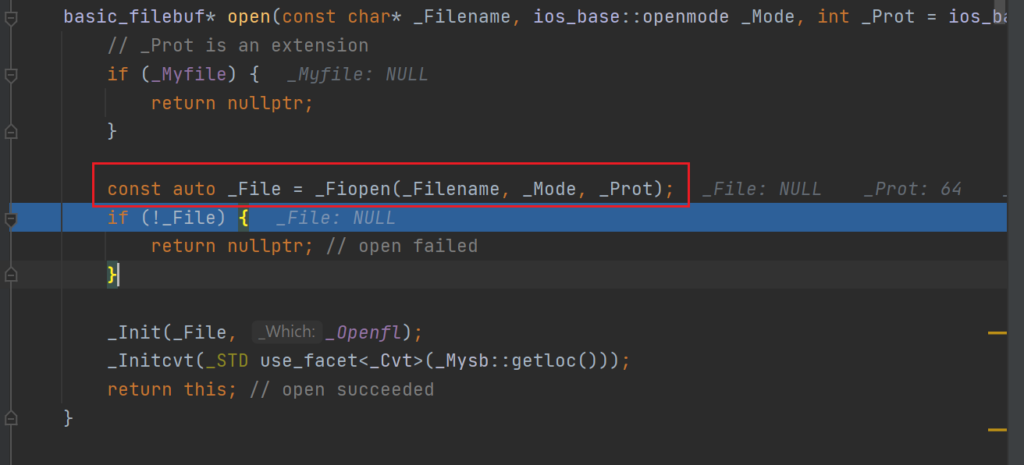
所以可以得知:MSVC(微软的 C++ 编译器)内,std::ifstream 内部是用 _Fiopen 打开文件的。因为微软的 STL 实现现在已经开源了,所以我们可以在 github 上找到这个函数的实现:
STL/fiopen.cpp at main · microsoft/STL · GitHub
可以从代码里看到,_Filename 为 const char * 时,_Fiopen 底层最终是用 _fsopen 实现的:
_fsopen, _wfsopen | Microsoft Docs
有关 _fsopen 的文档没有描述什么,但我们可以看看 fopen 的描述文档:
fopen, _wfopen | Microsoft Docs
The
fopenfunction opens the file that is specified by filename. By default, a narrow filename string is interpreted using the ANSI codepage (CP_ACP).
也就是说,fopen 会把我们传入的 char* 字符串作为 ANSI 编码来解析,而我们传入的字符串其实是 utf-8 编码,用 ANSI 来解 utf-8,自然只会得到一些莫名其妙的乱码,也无法获得正确的文件路径了。
虽然官方文档里没有明说 _fsopen 的 char* 字符串会被作为什么编码解析,但是根据 WinAPI 的一般性以及我实际测试的表现,_fsopen 和 fopen 对于文件路径的处理是一致的,都是解析为 ANSI,然后得到乱码。
到这里,我们的解决思路就很清晰了,把路径从 utf-8 string 转换为 utf-16 wstring,再调用宽字符版本的 API 即可。
但这里标准库的构造函数会自动帮我们选择宽字符版本的 API,所以只需要做第一步即可:

用 C++ 标准提供的 API 能够达到效果。
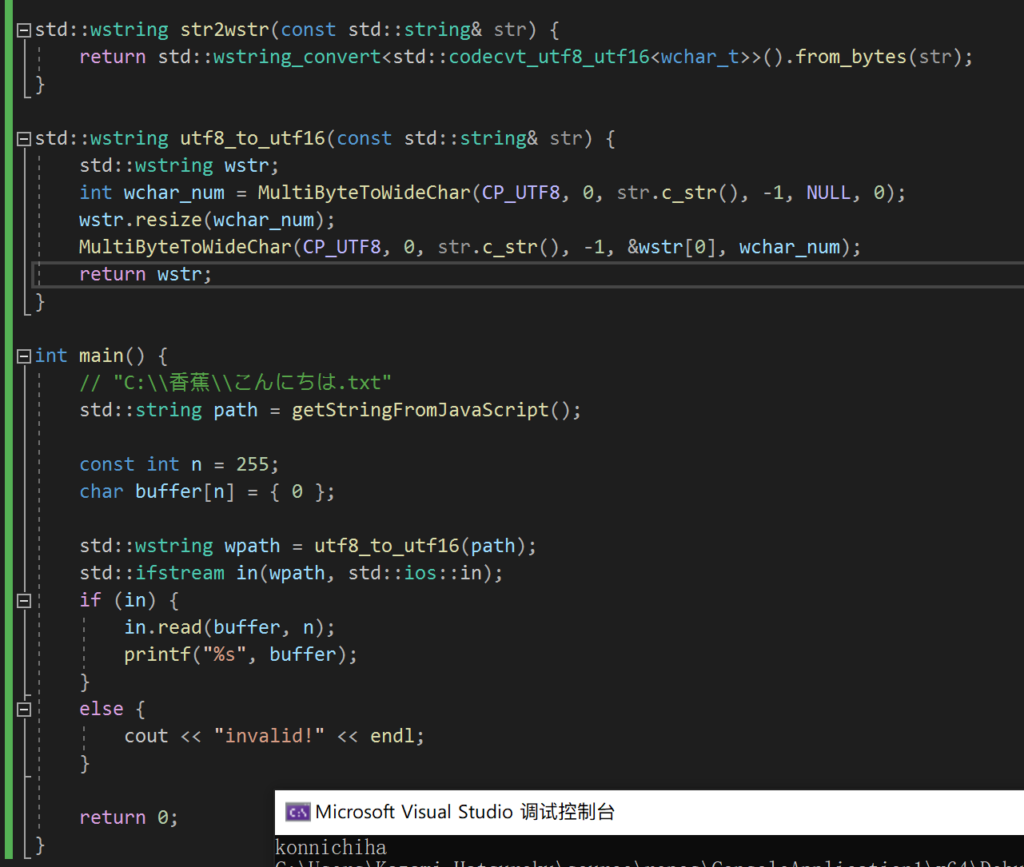
用 Windows 提供的 API 也能达到效果。
至此,问题就得到解决了。
* 10/10 有价值的专家文章
写程式不过是侦探魔法师的副业罢了