
如果你刚好学习过 C/C++ 编程,又刚好用了 Windows 系统的电脑,又刚好使用了 Visual Studio 进行代码的编写,又刚好在里面写了中文字符串或者引用了中文文件路径,又刚好有在 windows 的命令行里输出过中文字符串内容,那么你很有可能遇到过乱码问题。
曾经,作为一个技术不深的大学生,没有能力也没有想法去探讨这些问题的根本原因,如今我工作了,虽然技术还是不深,但是依然有工作逼着我去探讨这些问题的根本原因,不然测试就要给我挂一个大大的 bug 单了,没办法,只能够进行探索了。
这次遇到的问题是:同样是 utf-8 编码的源代码文件,在 Visual Studio 里面,字符串字面量在内存里是 GBK 编码,而在 CLion 里是 utf-8 编码。而且 CLion 中的 utf-8 编码还可能有损失。
前置知识
在上一篇文章 使用宽字符解决 Windows 路径乱码问题 —— 没那么深入理解 Windows 下C++ 字符串编码 – 梁小顺 (kazamihatsuroku.top) 里,介绍了 Windows 常见的字符编码:ANSI 和 utf-16。这里需要一些里面说过的前置知识,没看过的可以去看看。
出题篇
好像相同但又不相同的两份源代码
1 . 打开 Visual Studio 2022,创建一个新的 C++ 控制台项目
2. 打开 CLion,创建一个新的基于 CMake 的 C++ 项目,指定使用 1 中的编译器作为默认编译器。在 File -> Settings -> Build, Execution, Deployment -> Toolchains 里可以设置。
3. 选择一个经典名句作为我们的测试字符串:
int main() {
char str[] = "まどか: 这种事情绝对很奇怪啊";
printf("%s", str);
return 0;
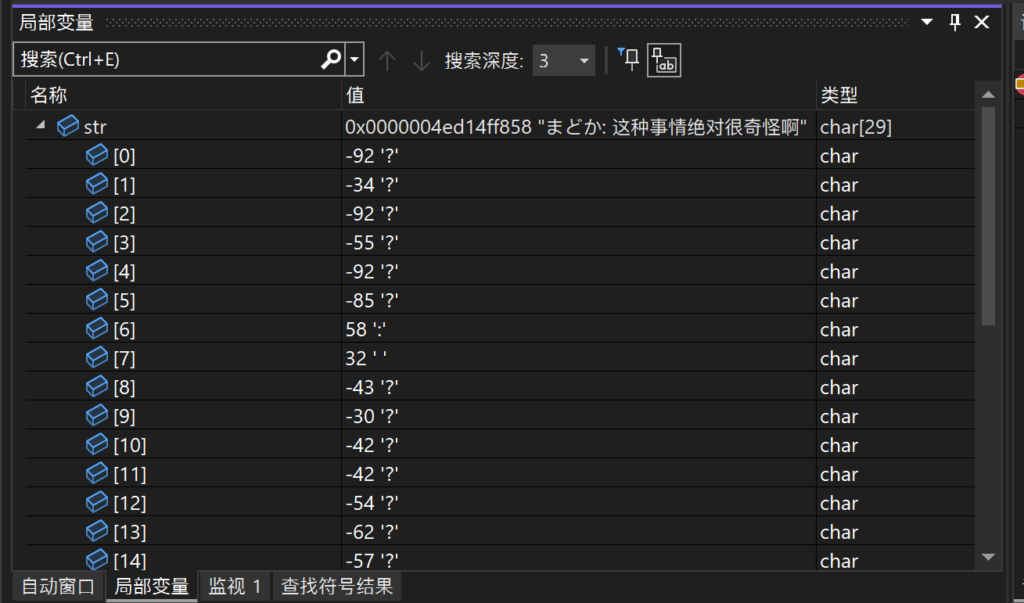
}在 Visual Studio 里,字符串在内存里是这样的:
在 Clion 里,字符串在内存里是这样的:
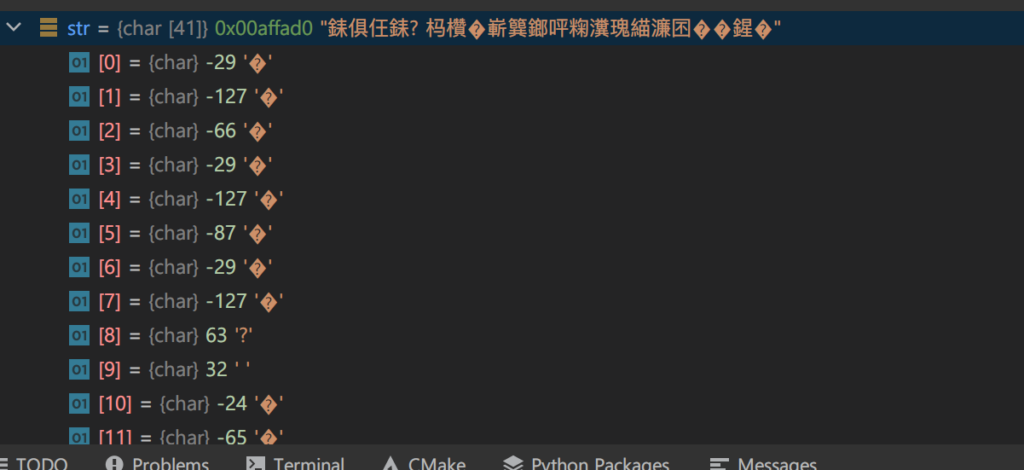
Visual Studio 中字符串长度为 29,Clion 中长度为 41,再加上前几个字符的值不一样这两点来看,它们内部编码肯定是不一样的。
那么这两个分别是什么编码呢?这时候又得祭出我们的 python 脚本来协助分析了:
def pdec(str, encoding):
encoded = str.encode(encoding)
byte_list = []
for c in encoded:
if (c >= 128):
byte_list.append(c - 256)
# byte_list.append(c)
else:
byte_list.append(c)
print(" ".join("{:d}".format(c) for c in byte_list) + "\n")
def putf16(str):
encoded = str.encode('utf-16le')
byte_list = []
for i in range(0, len(encoded), 2):
byte_list.append(encoded[i + 1] * 2 ** 8 + encoded[i])
print(" ".join("{:d}".format(c) for c in byte_list) + "\n")
def phex(str, encoding):
encoded = str.encode(encoding)
print(":".join("{:02x}".format(c) for c in encoded) + "\n")
path = 'まどか: 这种事情绝对很奇怪啊'
pdec(path, 'gbk')
pdec(path, 'utf-8')
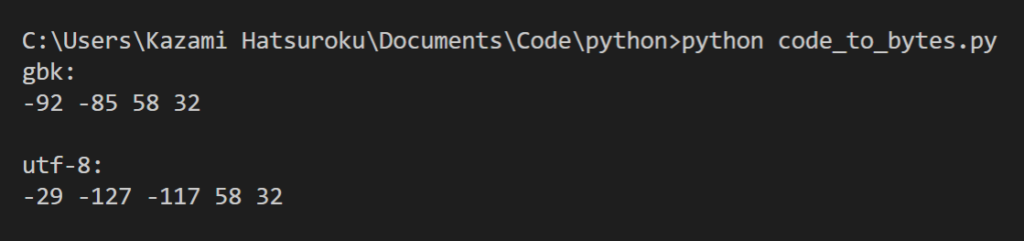
putf16(path)先用几个最常见的编码来猜猜,gbk、utf-8 和 utf-16:

通过对比之后我发现,Visual Studio 内用的是 GBK 编码,而 Clion 里面用的是 utf-8 编码……吗?不对,Clion 里面有点不对劲。
在 CLion 里,字符串的内存和 utf-8 编码基本上是可以一一对应的,除了这里:

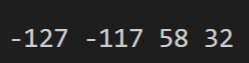
本该是 -127 -117 58 32 的地方,变成了 -127 63 32。为什么会这样呢??
字符串在内存里的真身
在逐字缩减之后我发现,这一段刚好就是「か: 」这一段(注意冒号后面有个空格,空格的数值是 32)。那么缩减字符串后再次分析:
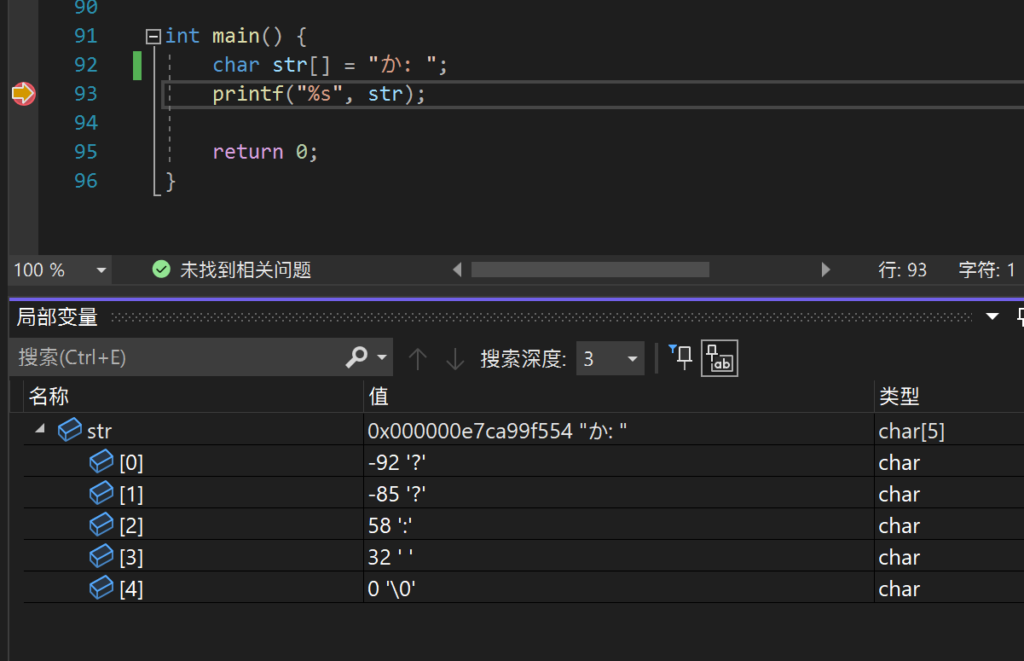
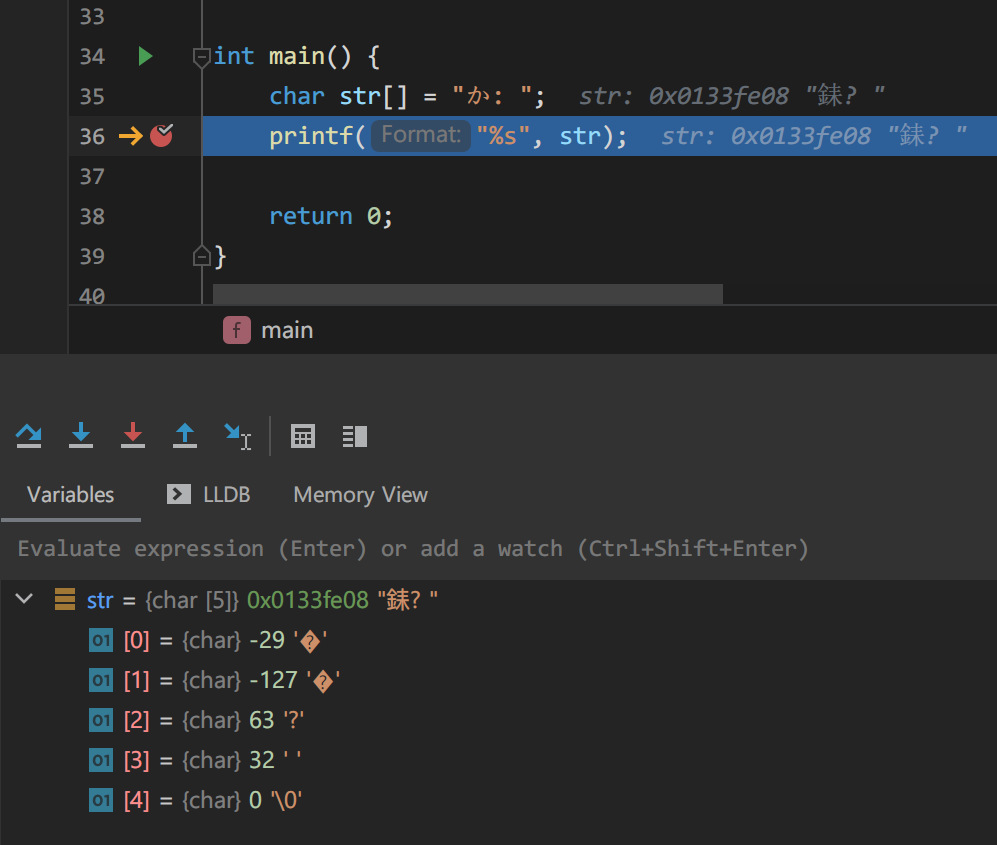
通过这三张图可以得出这么一个结论:
Visual Studio 中的字符串常量在内存里的编码恰好就是 GBK 编码,而 CLion 中的编码则是损坏(?)后的 utf-8。
为什么会这样呢?难道是因为 Visual Studio 编辑器对源代码的编码是 GBK,而 CLion 对源代码的编码是 utf-8 吗?如果是这样,那为什么 CLion 中的 utf-8 字符串常量编码会受到损坏呢?
我们用 Visual Studio Code 分别打开这两个文件,看看到底是用的什么编码。
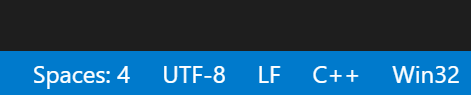
可以看到,CLion 源代码用的是 utf-8 编码。

Visual Studio 则是 utf-8 with BOM……?这啥意思?Visual Studio 的源代码不是 GBK 编码?BOM 又是个什么东西?
此处省略一大段我的收集资料和推理过程,直接给大家进入解题篇吧。
解题篇
BOM 是什么
TL;DR
BOM 是一个值,其值为 feff,可以被添加到字节流或者文本文件的开头,从而表示该流 / 文本的字符集为 Unicode,同时也说明编码顺序。utf-16 需要有 BOM 才可以正确解析,utf-8 要不要都无所谓。
详细解释
BOM 全称 Byte Order Mark。是 Unicode 中已定义的一个字符,其值为 U+feff。用法是:出现在字节流的开头,用于标识字节序。
这是什么意思呢?
如果有学习过计算机组成原理的话,应该都会知道,内存里面的基本单位是字节,所有的数据都会被分为一个一个字节,如果数据大于一个字节,则需要按照一定的顺序被切成一个一个字节存储到内存里。而字节的存储顺序分两种:大端和小端。
X 端的意思就是数值的较 X 部分会被放在较低的地址里。
使用大端还是小端主要由 CPU 决定,目前 x86 家族的 CPU 基本用的都是小端。
举个例子:

那么这个和 BOM 又有什么关系呢?
utf-16 编码字符的规则是:使用 2 个字节或者 4 个字节储存。也就是说,一个 utf-16 编码的字符会被切割成 2 个字节或者 4 个字节。如果小端机器只和小端机器通信,大端机器只和大端机器通信,那么 utf-16 编码数据的传输过程中不会有解码错误的问题,因为它们的解码顺序是一致的。但是如果大小端机器相互通信的话,则需要一种机制表明字节的存储顺序。这种机制就是 BOM。
feff 用小端表示就是 0xff、0xfe。如果大端的机器收到了,则会按照大端序解读成 fffe,但在 Unicode 中,U+fffe 被定义为「非字符」,不应该出现在文本中。所以大端机器会解释 0xff 0xfe 为「小端序的 BOM」,从而把字节流按照小端序解码,得到正确的内容。
其中 utf-16le 和 utf-16be 分别规定为「小端序的 utf-16」和「大端序的 utf-16」。
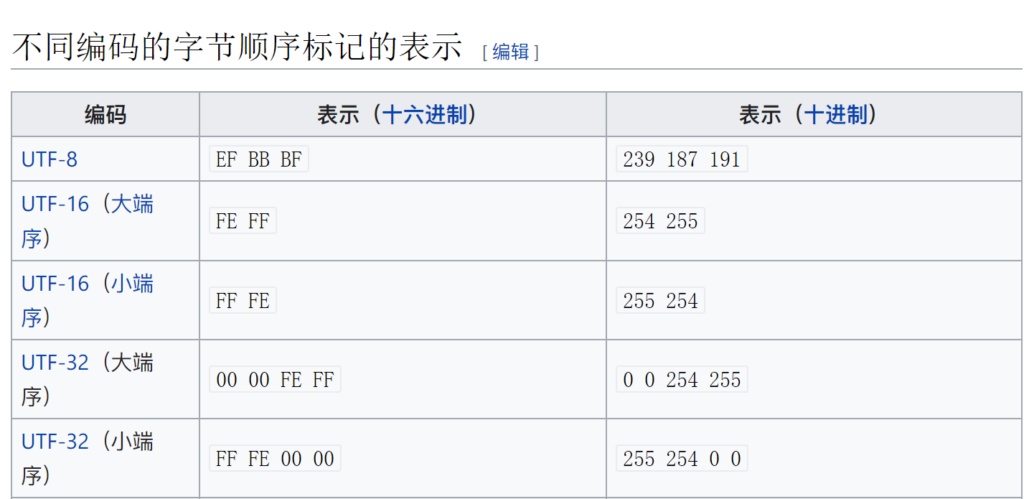
字节顺序标记 – 维基百科,自由的百科全书 (wikipedia.org)
也就是说,采用 utf-16le 编码的文本文件里,最前面的两个字节都会是 0xff 0xfe,utf-16be 则是 oxfe oxff。utf-8 如果带 BOM,则最前面的三个字节是 0xef 0xbb 0xbf。
为什么 utf-8 不用带 BOM 呢?因为 utf-8 是变长编码,本身的基本单位就是一个字节,所以无论大端小端都可以被正确解码。
MSVC 的小把戏
首先,微软在 Windows 平台提供的 C++ 编译器叫 MSVC,全称是 Microsoft Visual C++。MSVC 和 GNU gcc 还有 clang 一样,都是 C++ 的编译器。但既然 MSVC 是微软的产品,并且主要在 Windows 平台上使用,那么使用方式自然和类 unix 平台是相差很多的。
其中,在 MSVC 的官方文档中,提到了这么一个事情:
You can use the
/execution-charsetoption to specify an execution character set. The execution character set is the encoding used for the text of your program that is input to the compilation phase after all preprocessing steps./execution-charset (Set execution character set) | Microsoft Docs
By default, Visual Studio detects a byte-order mark to determine if the source file is in an encoded Unicode format, for example, UTF-16 or UTF-8. If no byte-order mark is found, it assumes that the source file is encoded in the current user code page, unless you used the/source-charsetor/utf-8option to specify a character set name or code page.
简单来说,源代码的字符编码和运行时字符串在内存中的编码不一定是一样的。例如在我们的这个例子里,Visual Studio 中源代码的编码是 utf-8 with BOM,但是运行时字符串在内存中的编码是 GBK,两者是经过转换的。
MSVC 的默认行为是:如果源代码有 BOM,那么就认为这份源代码是用对应的 Unicode 格式编码的。因为 utf-8、utf-16le、utf-16be 的 BOM 都不一样,所以看 BOM 就能分辨出用的是哪种 Unicode 编码格式。
但如果代码没有 BOM,那么就认为该源代码的编码为当前代码页指定的编码,在我的电脑上,这个编码为代码页 936,也就是 GBK 编码。
By default, when the compiler encodes narrow characters and narrow strings, it uses the current code page as the execution character set. Unicode or DBCS characters outside the range of the current code page get converted to the default replacement character in the output. Unicode and DBCS characters are truncated to their low-order byte, which is almost never what you intend.
execution_character_set pragma | Microsoft Docs
MSVC 的默认行为:窄字符(也就是 char)和窄字符串(也就是 char[])在运行时,会使用当前代码页的编码格式进行编码,如果源代码的编码为 Unicode,被转换成代码页编码格式后,并没有对应的字符,则这个字符会被替换成一个默认的替换字符。
可能这么听着有点拗口,那我们接下来以我们遇到的问题作为例子解释:
我们在 Visual Studio 中创建的文件,其编码为带 BOM 的 utf-8,MSVC 在编译时,可以通过 BOM 认出该文件是用 utf-8 编码的。源代码中的字符串字面量在可执行文件中的编码被转为 GBK,也就是当前代码页的编码。
而 CLion 中创建的文件,则是一般的没有 BOM 的 utf-8,MSVC 在编译时,无法分辨该源代码是什么编码,于是用便认为该文件用的是当前代码页编码,也就是 GBK 编码。
由于一般的代码文件中,除了注释外,基本都不会出现非 ASCII 字符,而 utf-8 和 GBK 都是兼容 ASCII 的,所以代码编译时并不会出现乱码导致的语法错误。
但源代码中的非 ASCII 字符串字面量,会被认为是使用 GBK 编码的,于是 MSVC 在编译时,因为 MSVC 认为源代码编码和执行编码都是 GBK,所以并不会做转换,而是保持其原本的样子保存在可执行文件中。
虽说是保持其原本的样子,但因为 Unicode 的字符集合比 GBK 的大,所以会出现一些 Unicode 字符无法被当做 GBK 编码字符解析的情况。

「か: 」的 utf-8 编码为 -29 -127 -117 58 32 ,而这几个字节会被 MSVC 以 GBK 的形式解析,GBK 在遇到超出 ASCII 范围的值时,会连同两个字节一起被当做一个字符解析,所以 MSVC 会这么切分:
-29 -127 | -117 58 | 32
转换成十六进制就是:e381 | 8b3a | 20。
e381 在 GBK 编码代表的是「銇」,就跟 Debugger 里显示的一样。
但 8b3a 就不一样了,GBK 编码规定:
GBK 采用双字节表示,总体编码范围为 8140-FEFE 之间,首字节在 81-FE 之间,尾字节在 40-FE 之间,不再规定低位字节大于 127,剔除 XX7F 一条线。
不知道哪来的牛逼站点
8b3a 的首字节是 8b,在 81-fe 之间,但是尾字节是 3a,不在 40-fe 之间。也就是说,8b3a 这个值表示不了任何的 GBK 字符,它是非法的。
这种情况该怎么办呢?还记得微软文档说的吗,看:
Unicode or DBCS characters outside the range of the current code page get converted to the default replacement character in the output.
当前代码页范围之外的 Unicode 或 DBCS 字符将转换为输出中的默认替换字符。
execution_character_set pragma | Microsoft Docs
所以,8b3a 会被转换成一个默认替换字符,在这里就是 3f,十进制写作 63,在 ASCII 表里代表问号 ‘?’。
所以,最终在内存里的编码是:-29 -127 | 63 | 32,并不是原本的 utf-8 值。
至此,问题得到解决。
总结
1 . 如果源代码文件用带 BOM 的 Unicode 编码,则字符串变量在内存里会被转换成当前代码页的编码。
2. 其他源代码的字符串变量在内存里会按照当前代码页的编码来存储,如果遇到了该代码页中不存在的值,则会用一个默认的字符代替,在我这里是用 ‘?’ 代替。